
Apache Kafka
Apache Kafka is a publish/subscribe messaging system designed to solve the problem of having many pub/sub systems. It’s known as a “distributing streaming platform”. The data is stored durably, it can be read deterministically and can be distributed within the system to protect against failure and opportunity for scaling performance.
Messages The Unit of Data in Kafka
Kafka works with a message which is like a row in DB perspectives, Kafka messages can also be accompanied by a key, if provided Kafka will try to get the hash of the key and put messages with the same key to the same partition. Deep into Kafka both the message and the key are byte arrays and they have no specific meaning to Kafka.
Kafka consumes messages in batches for the same topic and partition to improve efficiency but the larger the batch the longer it will take a message to propagate to all nodes/brokers, the batches are also compressed.
Kafka Schema
The main schemas of Kafka are JSON, XML and Apache Avro. Using key and message serializers you publish/consume a message to Kafka. Apache Avro (row-oriented remote procedure call & data serialization framework) is a different topic that requires a separate post.
Topics and Partitions In Kafka
We can think of a topic like a folder/directory in your computer, or as a table in a database, though, because of partitions/commit logs, it’s better to think of the topic like a folder/directory.
A topic can have 1-N partitions as shown in figure 1, partitions are like a log/file (commit log) in a folder, data are added in append order. Messages with the same key are written to the same partition(log file). The partition in a topic can be hosted on a different server to scale a topic horizontally. Partitions are also replicated to provide durability against server failure.
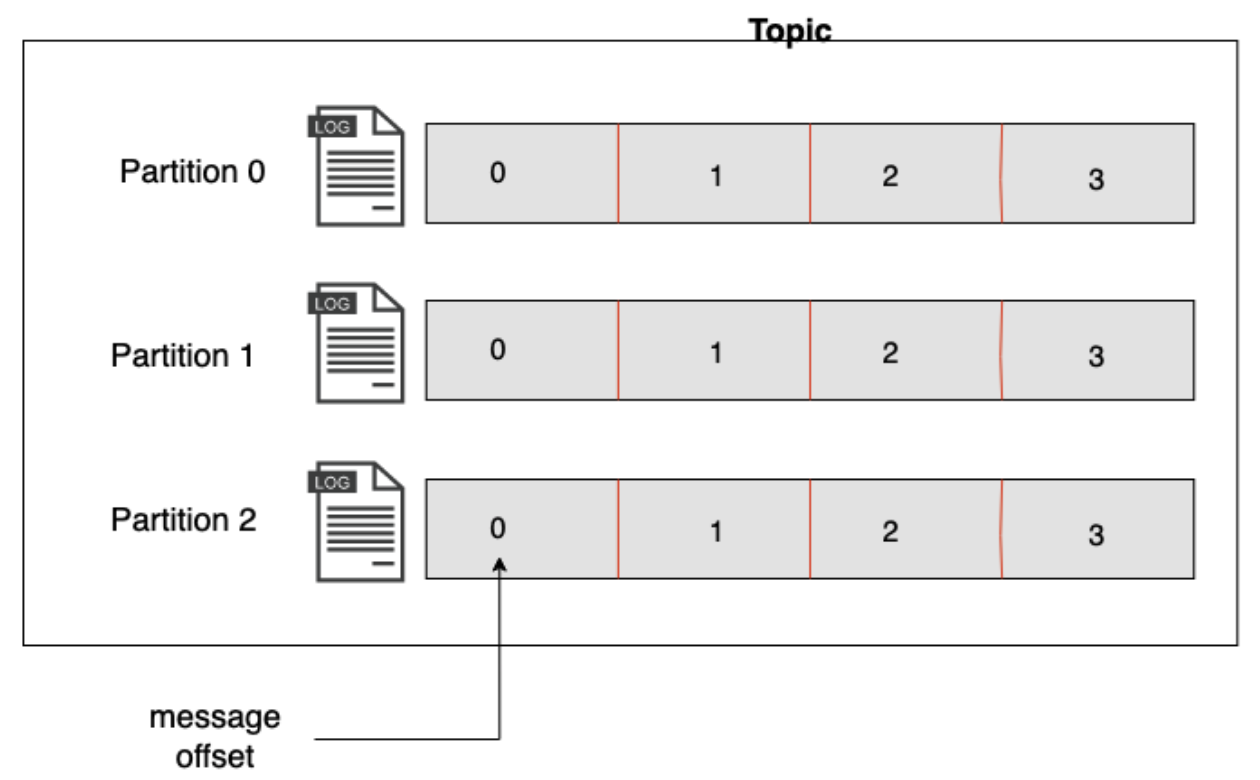 Figure: 1 Topic with 3 partitions
Figure: 1 Topic with 3 partitions
Topics are what are sometimes called streams in real-time data processing, you will have 1-N producers producing data in real-time to the topic and 1-N consumers consuming the data from the topic in real-time, though it doesn’t have to be real-time because Kafka commit-logs can be processed at any time.
Kafka Clients
The basic clients of Kafka are producers and consumers, though other clients are used for advanced data processing, such as Kafka Connect API. The advanced APIs also used producers and consumers at their core. The producers/publishers/writers are the clients that produce/send/write messages to the Kafka cluster and the consumers/subscribers/readers are the clients that consume/read/get messages from the Kafka broker and process them.
The producer subscribes to Kafka topic and produces messages to the topic and Kafka distributes the messages evenly to the partitions of the topic, if a message has a key then the message would be written to a partition based on the hash generated from the message key and subsequent messages with the same key would be written to that partition.
Consumers can subscribe to one or more topics and consume messages from the topic partitions. The consumer also keeps track of the processed messages through the message offset. An offset is an integer number generated by the broker in increasing order and attached to a message when a message is produced to Kafka, if a consumer fails, it can continue where it stopped when it’s back.
Consumers work in groups as shown in figure 2, and the partitions in the topic are distributed to the members of the group so that each member can consume only the partition assigned to it. This enables horizontal scaling of the consumers, and if a consumer fails the partition of the consumer is assigned to other consumers of the group to continue processing.
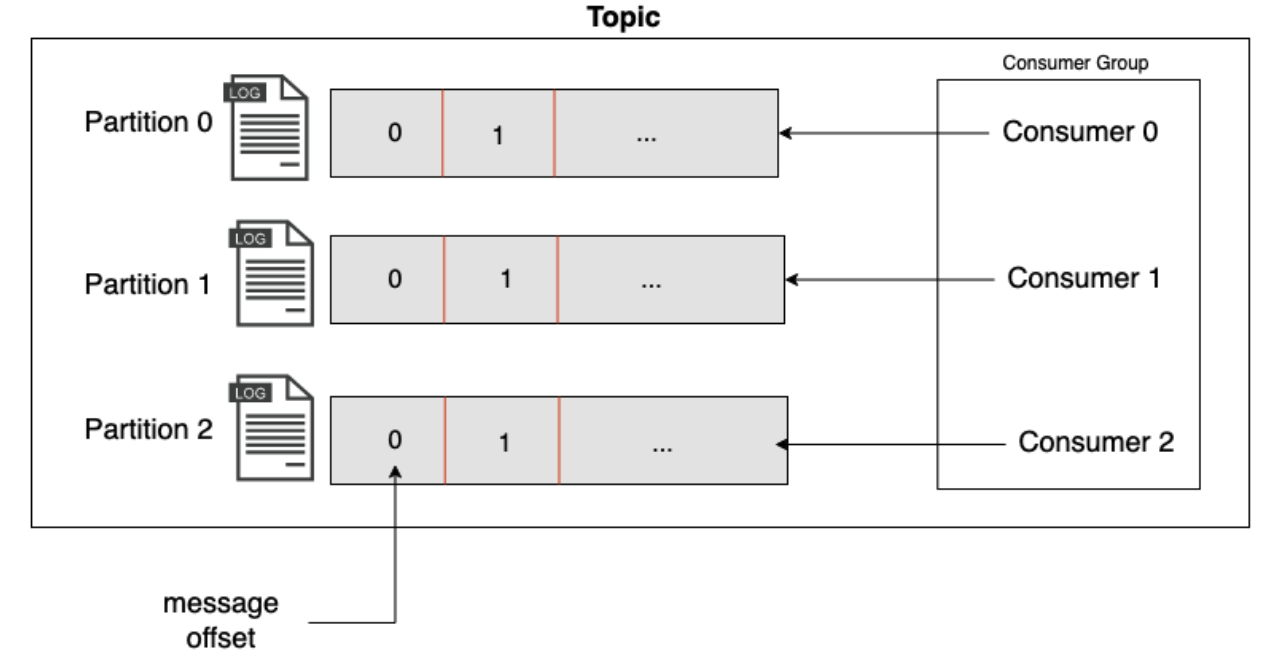 Figure: 2 Consumers group with 3 consumers each processing one partition
Figure: 2 Consumers group with 3 consumers each processing one partition
Conclusion
These are some of the basic components of Apache Kafka and how they operate, knowing how producers, consumers and brokers/clusters work are crucial to understanding Apache Kafka. Next, we will explore more about Apache Kafka broker/cluster.
Youtube Video
